I remember reading about Salesforce Big Objects before they became available and thought maybe it is an option to backup data present in regular objects. That is, instead of taking a backup via an ETL tool or data loader, maybe this will be an option to backup the data in the Force.com platform itself. Now that it is GA and I am reading more about it, i think the use cases for this are more varied.
Some use cases I can think of are –
- Archival of key data objects within the platform: You may want to use this option if you dont use any other means to backup key data. Also this may be an attractive option for non-large enterprise customers who dont themselves invest on large data warehouses or data lakes in their enterprise architecture.
Ex: customer history (if present in tasks and activities) will become huge over years but this is useful information for reporting & customer analysis.
- Store key information which is large volume in quantity and also high volume in transactional count so that it can be made available to query in smaller datasets within the platform. Ex:
- Data received via external source that you capture and trigger of processes. For ex: API provided event data from connected devices (unless you use Thunder)
- Customer financial account transactions that need to kept in the application for a multiple years due to compliance reasons
Important to remember, a Big Object does not have a UI of its own like a page layout. We will need to build the UI (lightning component or visualforce) for it. This would mean we will have to query the big object in Apex via SOQL or by pushing a smaller set of the big object’s data into another custom object via Async SOQL (check out –https://developer.salesforce.com/docs/atlas.en-us.soql_sosl.meta/soql_sosl/async_query_running_queries.htm)
There are a few things to keep in mind as one goes about designing a use case with the Big Objects feature. As i played around with this feature in my developer org, I captured the following as important notes.
- Big Objects support only certain types of fields – Text, LongTextArea, Number, Datetime and most importantly lookup fields also.
Note: Check out this great post by Alba Rivas on field workarounds to use while populating BigObjects (https://albasfdc.wordpress.com/2017/12/01/big-object-field-types-workarounds/)
- We will need to build a UI to display the data as a big object does not come with standard UI features.
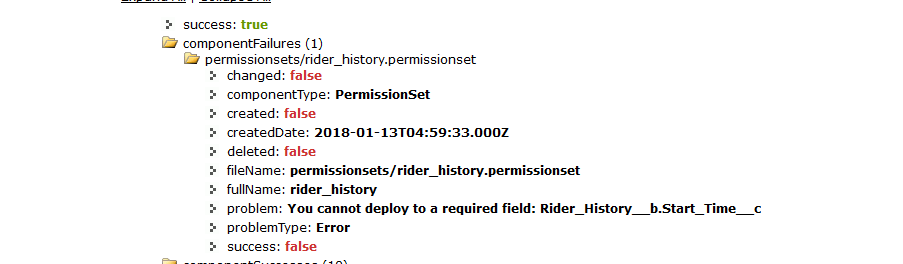
- While creating the object, we need to use the metadata api to create the object. this involves creating a deployment package with the definition of the object in a .object file. Also a .permissionset file should be prepared to give access to the fields of the object via a permissionset. Note: One lesson i learned while creating the permissionset is that required fields in the object cannot be assigned permissions via the metadata api
- While designing the object, remember that if you wish you to display the data synchronously via SOQL, the index is everything. So think through the fields in the index very carefully. Next couple of points explain this.
- The soql query should include fields from the index in same order as defined in the index. Trying to query with a different field will produce errors as shown below –
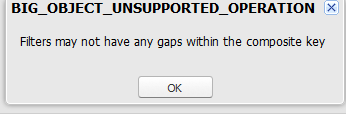

- The operators that can be used in the soql also has some restrictions. Comparison operators =, <, >, <=, >=, or IN can be applied on the last field in your query. Other prior fields in the index can support only = operator. These operators are not supported – !=, LIKE, NOT IN, EXCLUDES, and INCLUDES.
- When data is inserted into the big object, the data in the index fields determines if the new record will be inserted or updated.
- When the use case involves pulling larger amount of data and can be dealt with asynchronously, Async SOQL approach should be used. This applies also when we need to do aggregate functions on the data like COUNT, SUM etc
- Async SOQL is available to use only if some capacity is purchased for Big Objects. That means it is not free and will involve a discussion with the Salesforce account executive.
- Async SOQL seems to support queries on non indexed fields also ( I could not test it myself as this feature is not available in developer orgs)

Overall, we can conclude this is an awesome feature that has been added to the platform. This will grow in use as customers find more use cases for it. Salesforce as a platform has matured and is being used in many large clients where the volume of data in the org is increasing every year. Instead of investing in more on premise solutions or other platforms, clients can use their existing platform, team skills etc to utilize Salesforce for big data scenarios!
Thank you for your post. This is excellent information. It is amazing and wonderful to visit your site.
ReplyDeleteMachine Learning Training in Bangalore
Ai Full Stack Online Training in Bangalore
Thank you for this helpful content… Employee Background Verification ensures that the information provided by a candidate is accurate and trustworthy. It helps employers validate identity, education, employment history, and criminal records—reducing hiring risks and building a reliable workforce.
ReplyDeleteReally informative article. Thanks Again. Really Great.
ReplyDeleteDocker with Kubernetes Online Training from India
SAP SuccessFactors Training
SAP SD Realtime Online Support In India
DevOps Free Live Online Demo Class
SAP S/4HANA CS Interview Questions & Answers
Azure Solutions Architect Online Training Institute from India, Hyderabad
Best SAP S4HANA EWM Online Training
SAP GTS Certification Online Training from Hyderabad
Oracle DBA 19c Training Course Online
Best SAP BASIS Online Certification Training India